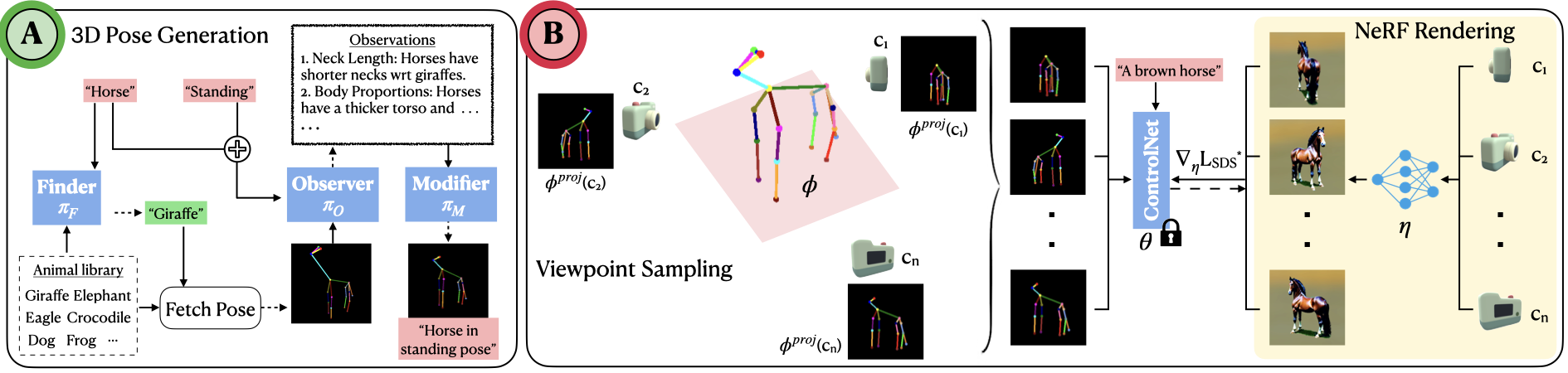
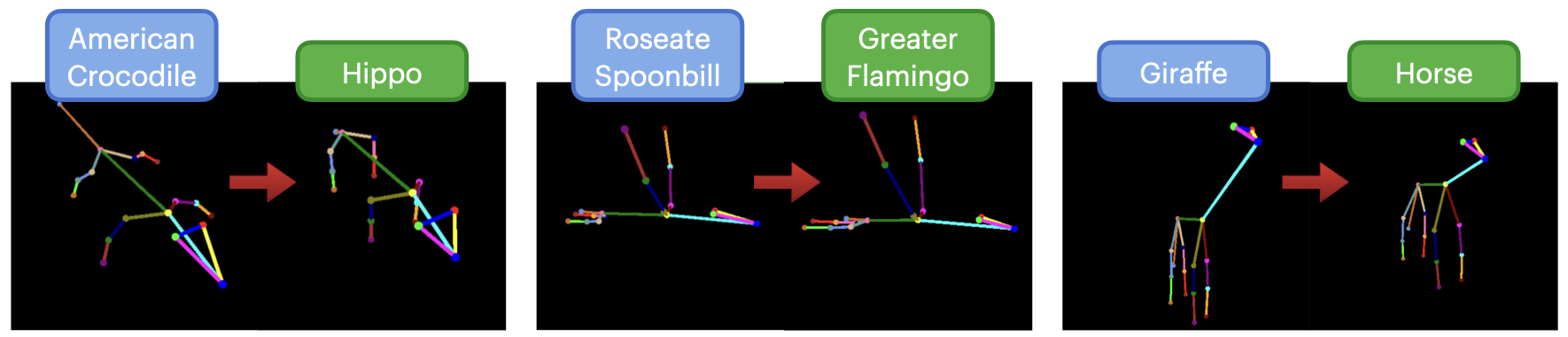
Abstract
3D generation guided by text-to-image diffusion models enables the creation of visually compelling assets. However previous methods explore generation based on image or text. The boundaries of creativity are limited by what can be expressed through words or the images that can be sourced. We present YouDream, a method to generate high quality anatomically controllable animals. YouDream is guided using a text-to-image diffusion model controlled by 2D views of a 3D pose prior. Our method generates 3D animals which are not possible to create using previous text-to-3D generative methods. Additionally, our method is capable of preserving anatomic consistency in the generated animals, an area where prior text-to-3D approaches often struggle. Moreover, we design a fully automated pipeline for generating commonly found animals. To circumvent the need for human intervention to create a 3D pose, we propose a multi-agent LLM that adapts poses from a limited library of animal 3D poses to represent the desired animal. A user study conducted on the outcomes of YouDream demonstrates the preference of the animal models generated by our method over others.